이 프로그램은 안전신문고 교통위반 신고내역을 크롤링하여 DB로 저장하고 엑셀파일(xlsx) 및 구글 스프레드시트로 만들어 사용자가 자신의 신고내역을 편하게 관리할 수 있도록 하는 목적으로 제작되었습니다. 윈도우용 앱과 도커 이미지로 배포하고 있으며, 윈도우용 앱 다운로드는 Github에서 가능합니다.
Pyinstaller를 이용해 단일파일로 컴파일하는 특성상 바이러스로 오탐당하지만, 실제로는 바이러스가 아니니 안심하고 사용하셔도 됩니다.
소스코드는 Github에 모두 공개되어 있습니다.
Selenium Hub와 도커 이미지를 이용한 구동도 가능합니다. 모두 아래 단락에서 설명하겠습니다.
윈도우용 사용설명서
요구사항
윈도우용 안전신문고 크롤러를 사용하기 위해선 윈도우 환경 및 구글 크롬이 필요합니다.
이 프로그램은 텔레그램 봇과 구글 스프레드 시트 연동을 추가적으로 지원하며, 이를 사용하기 위해선 텔레그램 봇 작동에 필요한 token과 chat id, 구글 스프레드 시트 연동에 필요한 auth용 JSON 키파일과 권한설정이 완료된 스프레드시트의 URL주소가 필요합니다.
UI
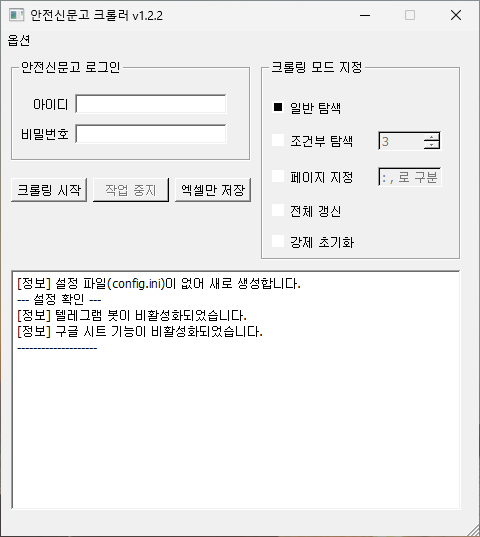
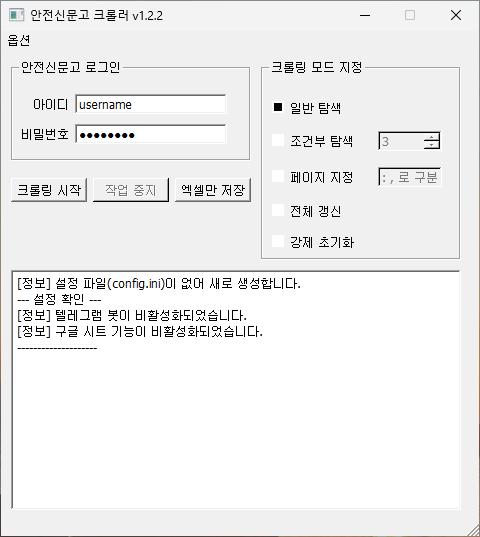
깃허브를 통해 다운로드 받은 mysafetyreport파일을 실행하면 아래와 같은 창이 나타납니다.
동시에 해당 폴더 하위에 data폴더를 생성하고 필요한 것들을 이곳에 저장합니다.
기본적인 기능 및 사용법은 아래와 같습니다.
- 아이디 / 비밀번호 : 안전신문고에 사용되는 ID와 PW를 그대로 입력하면 됩니다. 입력한 정보는
./data/config.ini에 암호화되어 저장됩니다. - 크롤링 시작 : 입력된 계정을 통해 안전신문고에 로그인 후 마이페이지 → 나의 안전신고현황을 크롤링하는 작업을 시작합니다. 기본적으로 ’30개씩 보기’를 선택하도록 되어 있습니다.
작동 방식에 대한 내용은 아래 기본 동작 단락을 읽어주세요. - 작업 중지 : 크롤링 작업을 강제로 중지합니다. 저장되지 않은 데이터는 유실됩니다.
- 엑셀만 저장 : 크롬을 띄우고 크롤링하는 과정 없이 현재까지 저장된 DB를 다시 엑셀 및 스프레드시트로 추출만 합니다.
- 일반 탐색 : 입력된 계정정보를 활용하여 안전신문고에 접속 후, 신고내역을 탐색하여 DB로 저장합니다.
- 조건부 탐색 : ‘나의 안전신고현황’ 페이지에서 ‘진행’상태인 신고건이 한 개도 없는 페이지를 ‘입력한 숫자’만큼 만나면 탐색을 종료합니다. 신고건수가 너무 많을 경우 불필요한 과거 신고건을 탐색하는 것을 막아줍니다.
- 페이지 지정 : 30개씩 정렬된 신고내역의 특정 페이지에 해당하는 신고건만을 크롤링합니다.
6:8이라고 적을 경우 6~8페이지,7,9라고 적을 경우 7페이지와 9페이지를 크롤링합니다. - 전체 갱신 : 답변완료된 건을 포함, 모든 신고내역을 처음부터 크롤링합니다.
- 강제 초기화 : DB오류 등이 발생했을 때 DB 전체를 지우고 처음부터 크롤링합니다.
기본 동작
기본적인 동작은 간단하게 계정입력 후 크롤링 시작을 클릭해서 작동합니다.
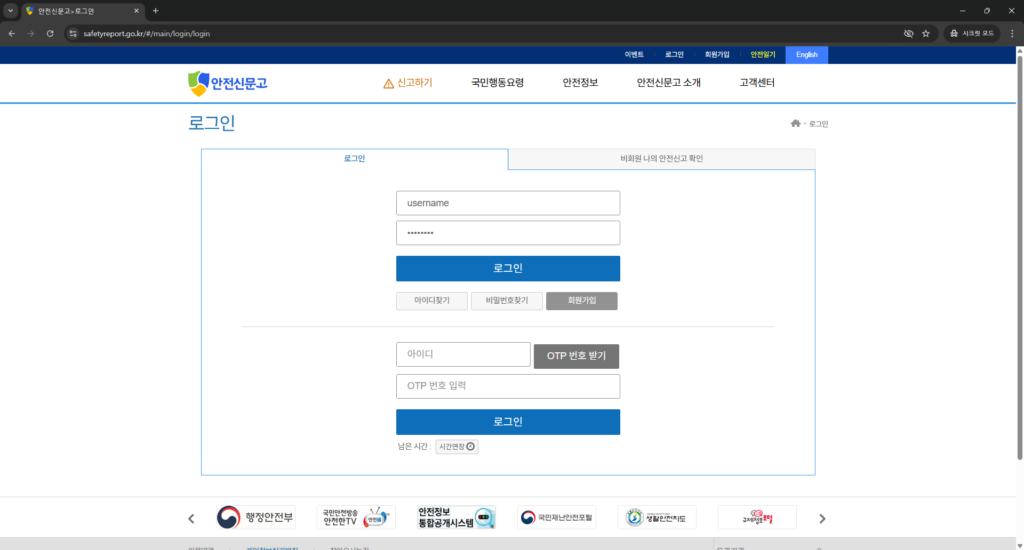
입력받은 아이디와 비밀번호를 이용해 자동으로 시크릿 창을 열어 로그인을 시도합니다.
절.대.로. 작동중인 크롬 위에 마우스 커서를 올리거나 크롬을 직접 조작하지 마세요.
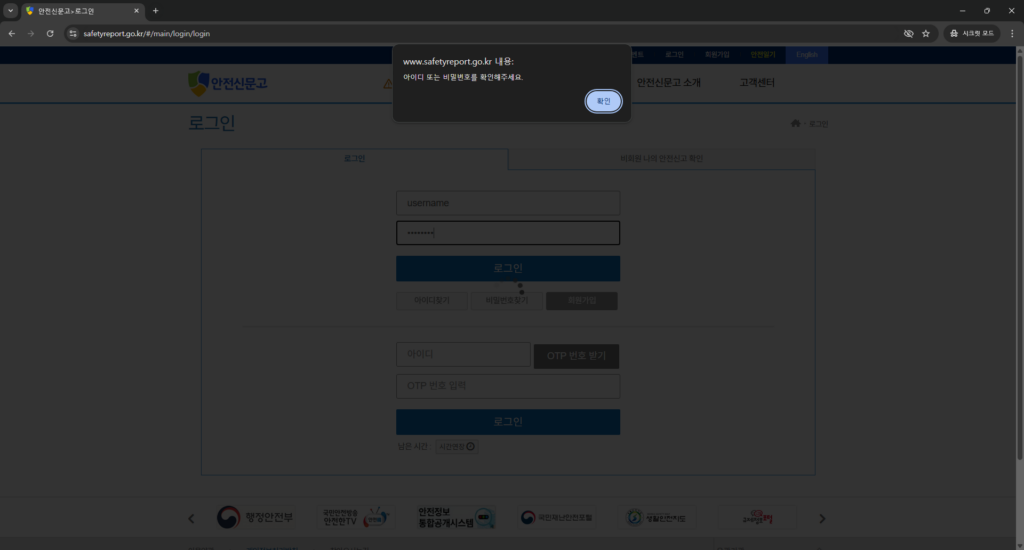
물론, 틀릴 경우 로그인에 실패합니다.
로그인에 성공한 뒤에는 아래처럼 신고내역 리스트 전체를 순회하며 목록을 작성한 후,
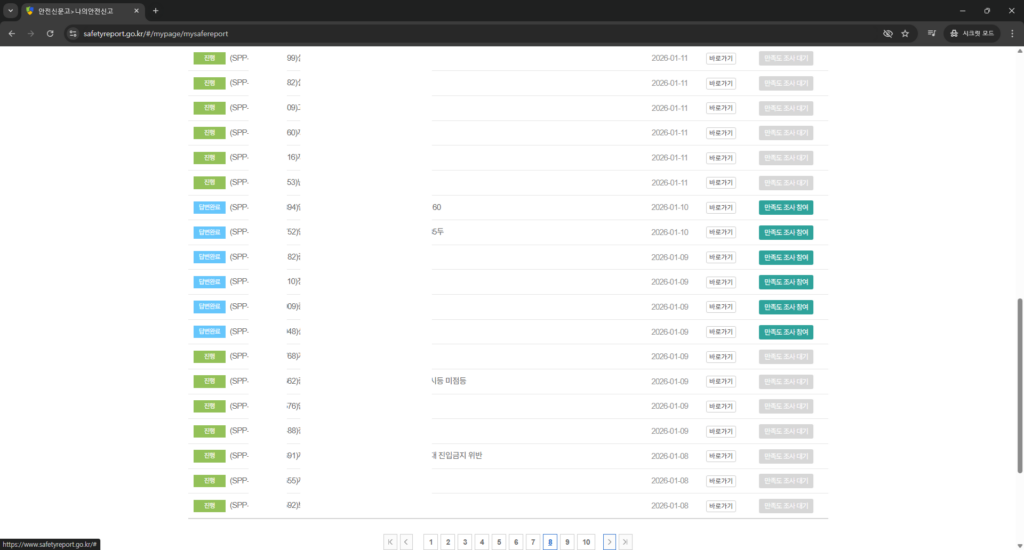
작성된 목록을 기반으로 개별 신고건을 모두 순회하며 신고내용과 담당자 답변내용 등을 긁어 교통위반 내역을 파싱합니다.
최초 실행 시엔 모든 신고건을 순회하겠지만, 최초DB가 작성된 이후엔 답변완료된 건이나 취하 건 등은 더 이상 접근하지 않습니다(변경내역이 없으므로).
모든 신고내역 순회가 끝나고 DB로 저장된 후에는 ./data폴더 하위에 data.db로 저장되며
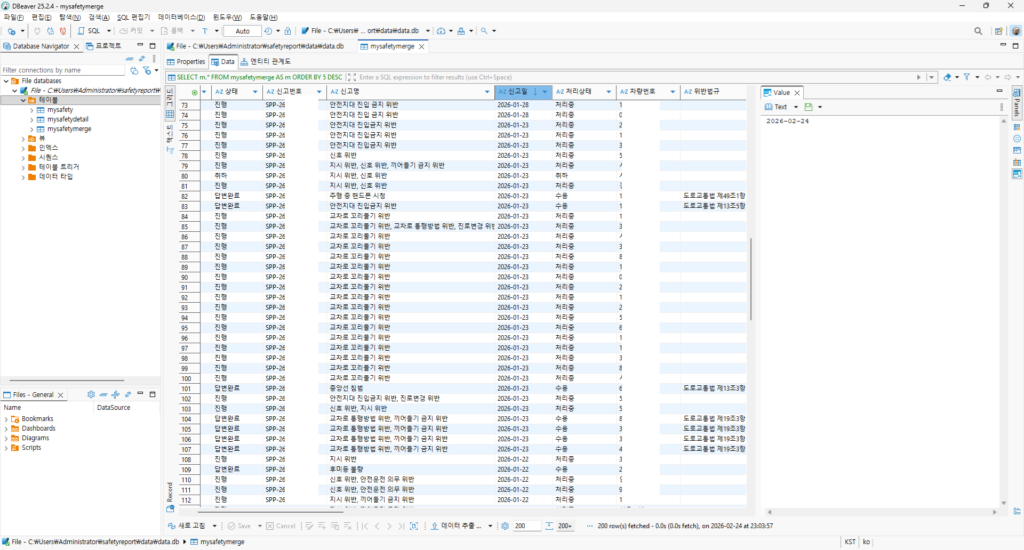
쿼리를 조금 건드릴 수 있으신 분은 DBeaver나 DB Browser for SQLite를 통해 직접 들여다보고 편집할 수 있습니다.
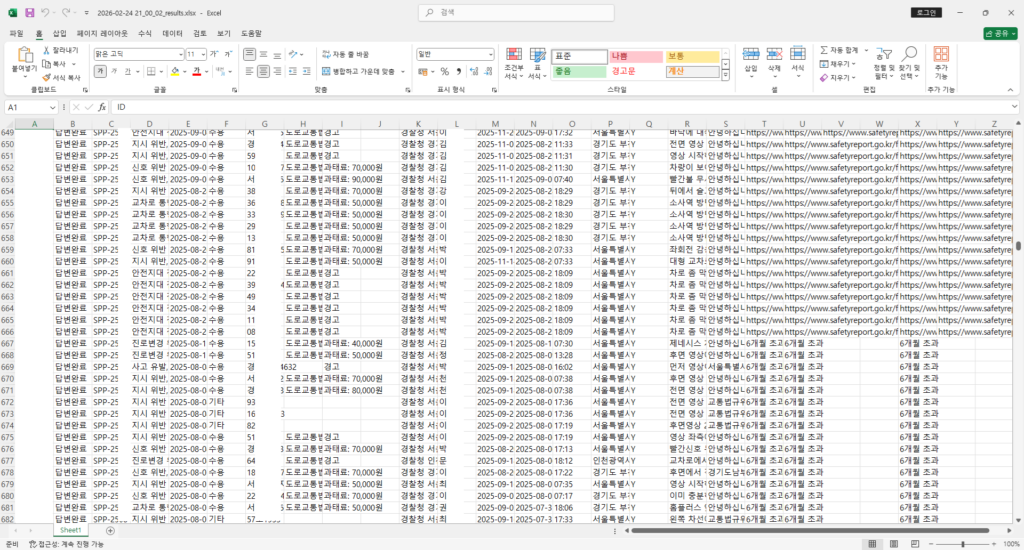
기본적으로 매 작업마다 ./data/results폴더 하위에 엑셀파일을 만들어 줍니다.
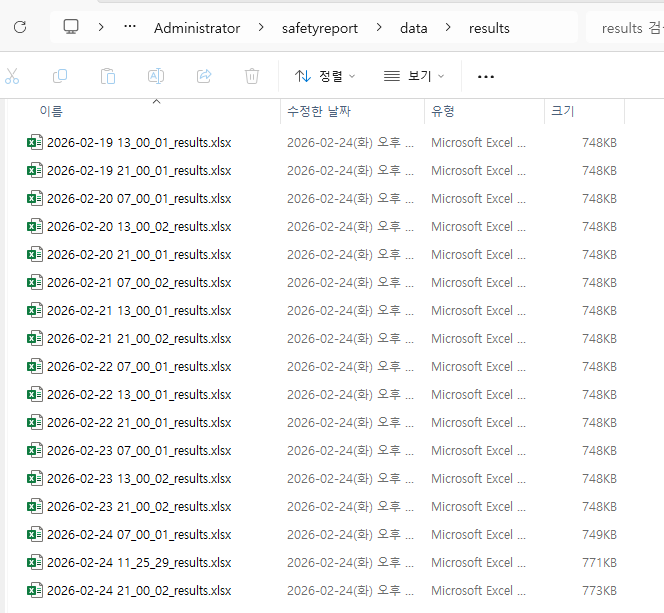
각 신고건들의 신고번호, 진행상태, 차량번호, 위반법규명, 담당자, 과태료 등의 컬럼으로 내용이 정리되어 있어 익숙한 엑셀함수로 자신의 신고내역을 지역별, 담당자별, 위반법규별로 통계처리 및 분석할 수 있습니다.
추가 동작
스프레드 시트 연동
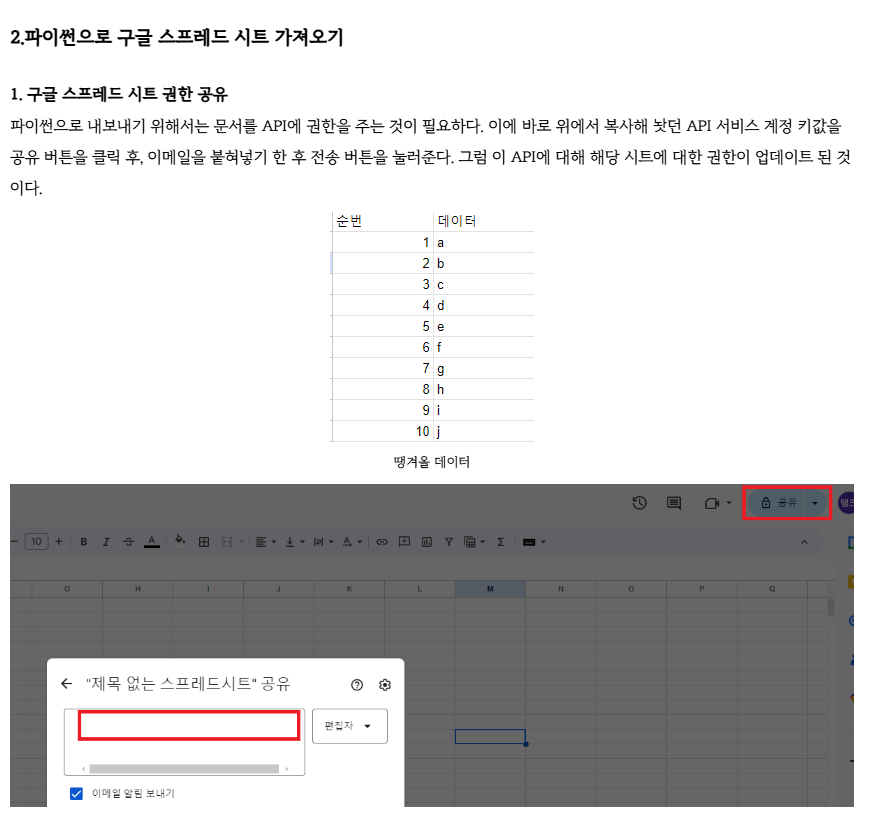
본 프로그램은 구글 스프레드시트 연동을 지원합니다. 이를 위해선 먼저 이 블로그에서 상세히 설명하는대로 Google Sheets API 사용 설정 및 JSON 키파일을 발급하고, 빈 스프레드시트 문서를 생성 후 서비스 계정에게 권한을 할당해야 합니다.
아래 사진처럼 링크된 블로그의 “2. 파이썬으로 구글 스프레드 시트 가져오기 – 1. 구글 스프레드 시트 권한 공유” 부분까지 진행하시면 됩니다.
이후 주소창에서 docs.google.com/spreadsheets/d/ 이후의 부분을 복사한 뒤,

크롤러의 옵션 – 추가기능을 선택해
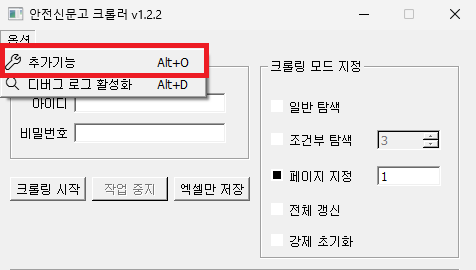
구글 시트 주소 란에 복사한 부분을 붙여 넣습니다. 예시글의 경우 1Gn3Yy9upbxGTIXmYBgopQANQRqPHC6vnej7lgPbGsC0가 되겠네요.
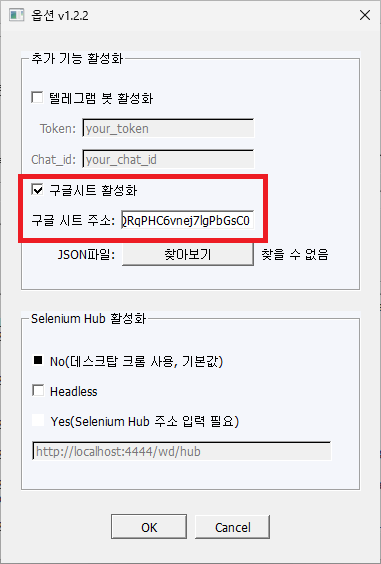
그리고 스프레드시트 준비 과정에서 다운로드 받은 JSON키파일을 찾아보기버튼을 클릭해 넣어줍니다(파일명은 다릅니다).
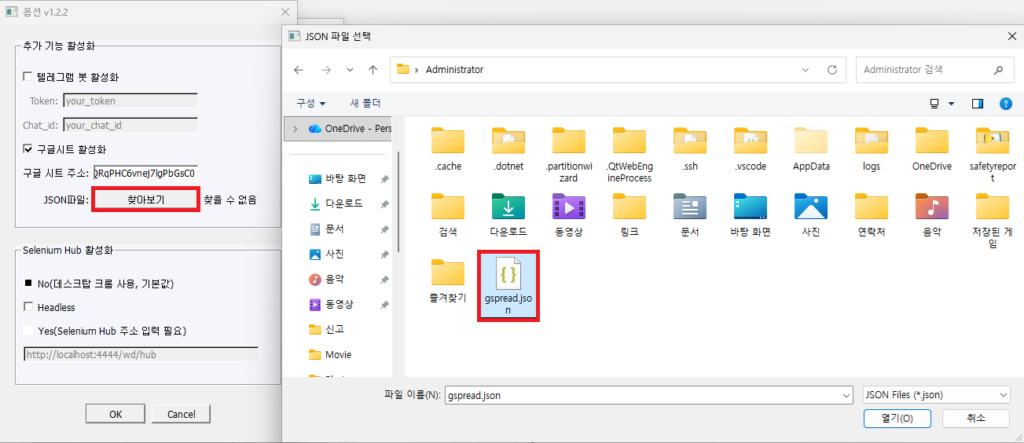
JSON파일의 형식을 검증하진 않기 때문에 아무 JSON파일을 지정만 해줘도 아래처럼 정상이라고 표시되긴 하나
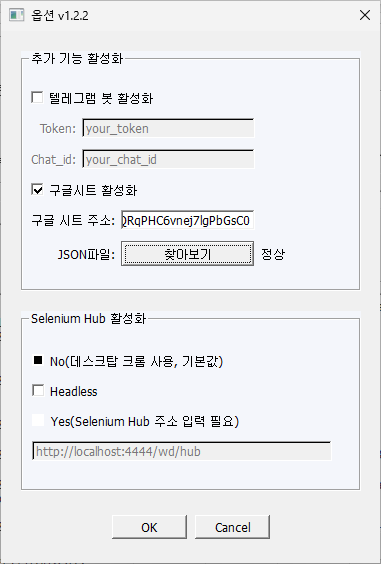
실제로 유효한 JSON파일이 아니라면 작동 시 오류가 나게 되므로 제대로 된 JSON파일을 지정해주세요.
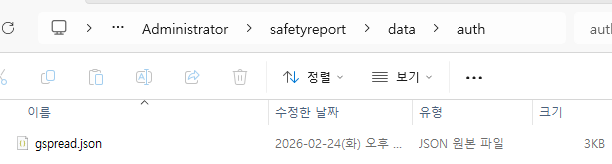
이렇게 지정된 JSON파일은 ./data/auth/gspread.json이라는 경로로 복사됩니다.
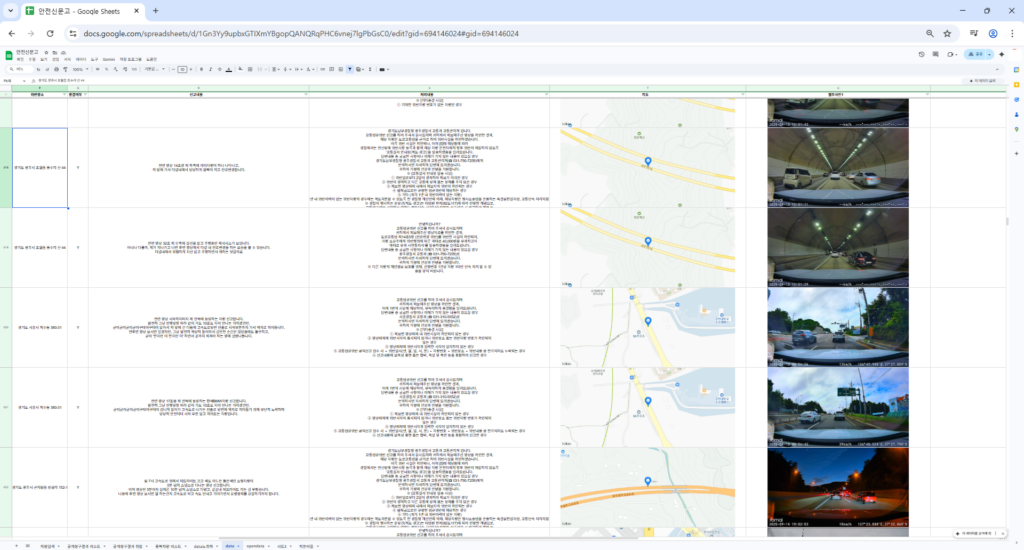
연동에 성공하면 지정한 스프레드시트문서에 data라는 시트를 만들고 엑셀과 동일한 내용을 업로드합니다.
엑셀과 차이점이 있다면, 엑셀파일은 시행할때마다 새로운 파일이 생성되는 것에 반해, 스프레드 시트는 data시트의 내용을 계속해서 업데이트합니다.
또한, 아래처럼 첨부파일 중 이미지(지도 포함)를 바로 표시해 준다는 장점이 있습니다.
같은 문서가 매번 업데이트 되므로, 여기서 다양한 함수를 통해 즉각 업데이트 되는 대시보드를 만들 수도 있습니다.
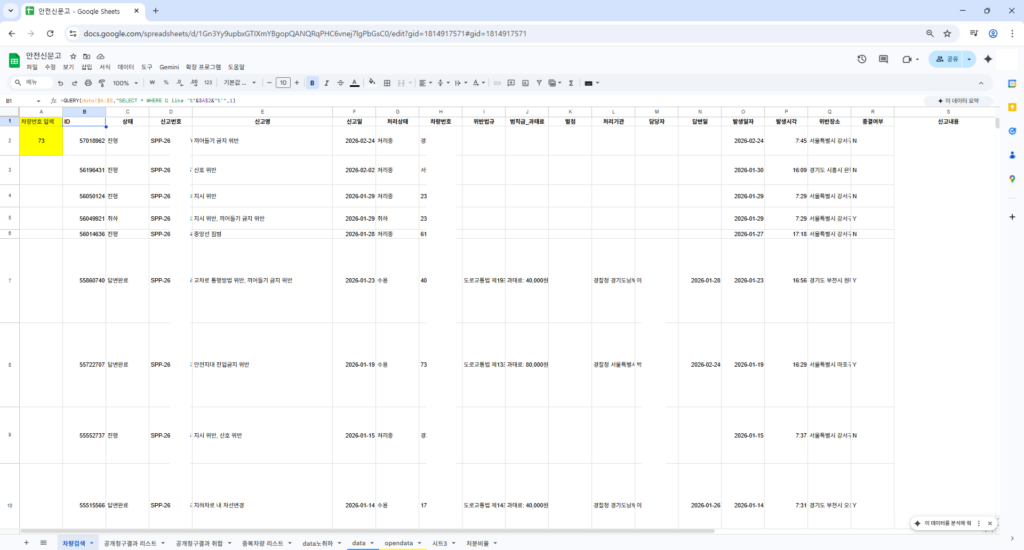
예를 들어, 아래처럼 스프레드시트의 함수를 사용해 문자열 일부에 해당하는 차량번호를 검색할 수도 있습니다. 신고 시 동일 위반 내역이 많다거나, 까방권은 이미 충분히 찢었음을 증명할 때 유용하게 사용할 수 있습니다.
혹은, 아래처럼 처리기관과 담당자별 처리건수와 처분건수를 비중으로 나누어 살펴볼 수도 있습니다.
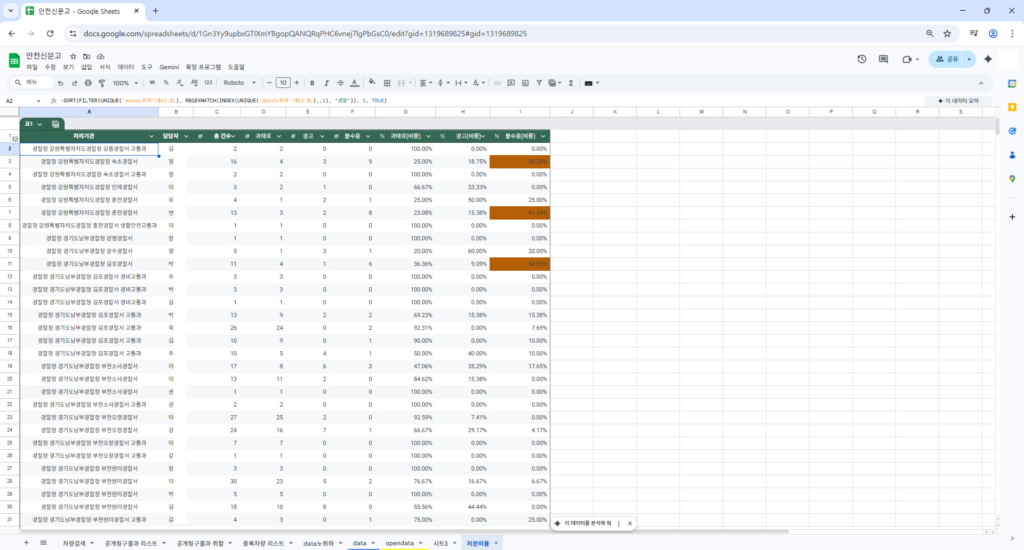
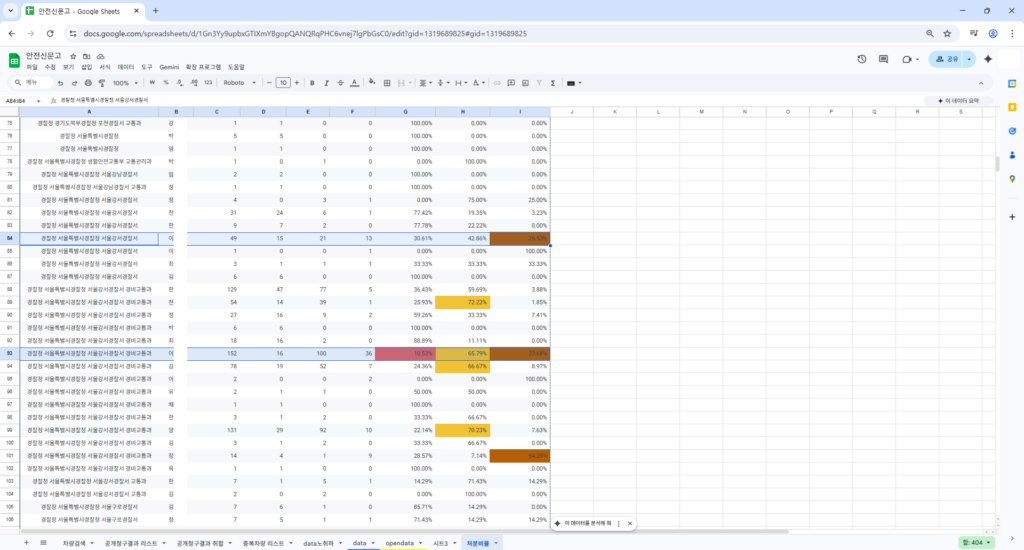
지나친 소극행정 혹은 업무태만자들은 이런 통계에서 쉽게 발견됩니다.
텔레그램 봇
옵션 중 텔레그램 봇에 필요한 값 2가지(Token, Chat_id)를 사용해 간단하게 텔레그램 봇을 작동시킬 수 있습니다.
텔레그램 봇을 만드는 방법은 인터넷 검색을 통해 쉽게 얻을 수 있으므로 패스합니다.
활성화시킬 경우 매 동작시마다 새롭게 추가된 신고번호를 알려주고, 새로 답변이 달린 건이 있을 경우 이에 대한 summary도 제공합니다.
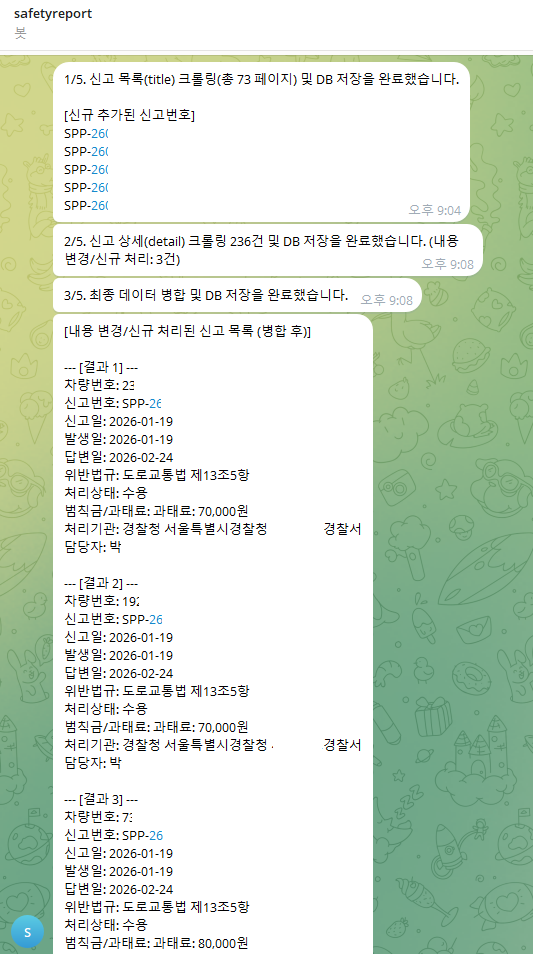
또한, /h를 입력하면 봇 메뉴를 호출할 수 있고, 여기서 차량 번호나 신고 번호 검색 등 간단한 검색을 수행할 수 있습니다.
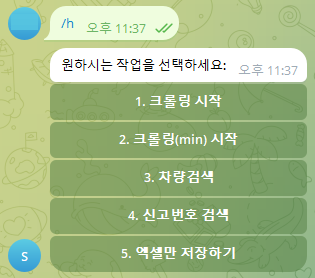
차량검색을 클릭 후 문자열 일부를 넣으면 해당하는 모든 차량번호의 신고건을 나열해 줍니다.
크롤링 시작은 말 그대로 원격에서 크롤링 작업을 지시할 수 있는 기능입니다.
단, 윈도우에 프로그램이 작동중이어야 합니다.
이 원격 크롤링 지시 기능은 윈도우보단 하단에서 설명할 도커 환경을 염두에 둔 기능입니다.
엑셀만 저장하기의 경우 프로그램 상의 엑셀만 저장과 동일한 기능으로, 현재 시점까지의 data.db파일의 내용을 다시 한 번 엑셀로 만들어 줍니다.
스프레드 시트가 연동되어 있다면, 스프레드 시트의 내용도 다시 업데이트 해 줍니다.
Headless옵션 & Selenium Hub
옵션 창 하단에는 아래와 같은 옵션이 있습니다.
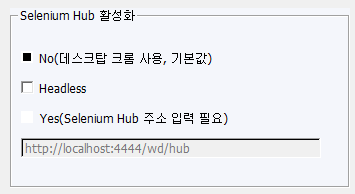
Headless의 경우 크롬창을 숨긴 상태로 작동하는 옵션입니다. 최초 몇 번 사용하며 안정적으로 작동하는 것을 확인한 후엔 Headless를 클릭해 크롬창을 숨겨 덜 불편하게 사용할 수 있습니다.
로컬 환경에 크롬을 설치하기 싫거나, 사용하기 어려운 상황이라면 Selenium Hub를 대신하여 사용할 수 있습니다. Selenium Hub의 주소를 입력하고 크롤링을 시작하면 로컬 크롬 대신 Selenium Hub를 사용해서 작업을 시작합니다.
그러나, 이 옵션을 사용할 경우 아래에 후술할 리눅스 도커 환경을 더 추천합니다.
로그 확인
./data/logs폴더 하위에 동작 로그가 기록됩니다.
로그에는 매 작동 단계에 대한 정보가 기록되어 있어, 혹시 오류가 발생해 중단되면 어느 부분이 문제였는지 파악할 수 있습니다.

디버그 로그 활성화기능을 체크한 상태로 작동시키면 어마무시한 용량의 로그가 생성됩니다. 제 신고건 기준으로 로그파일 한 개가 10메가 정도 합니다.
이 경우 다른 파이썬 라이브러리의 동작 내역까지 모조리 기록되므로, 트러블 슈팅을 위한 로그 공유는 이쪽이 좋습니다.
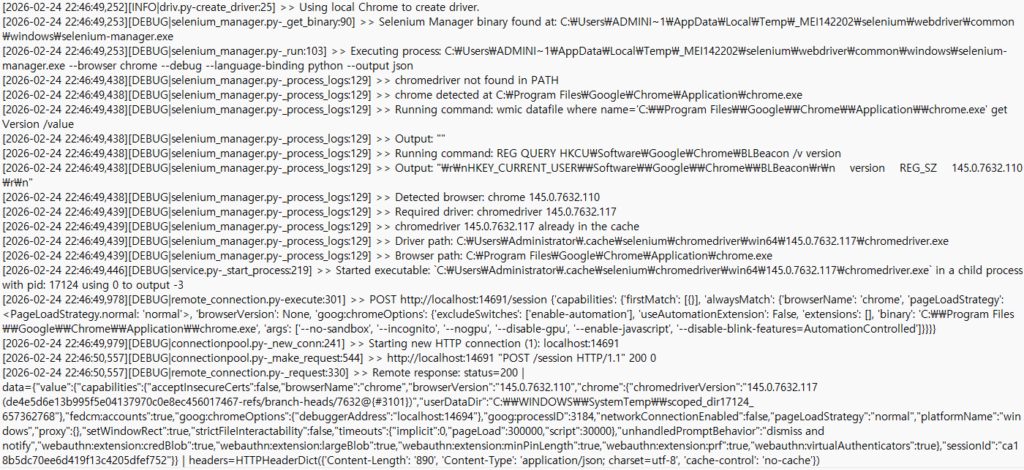
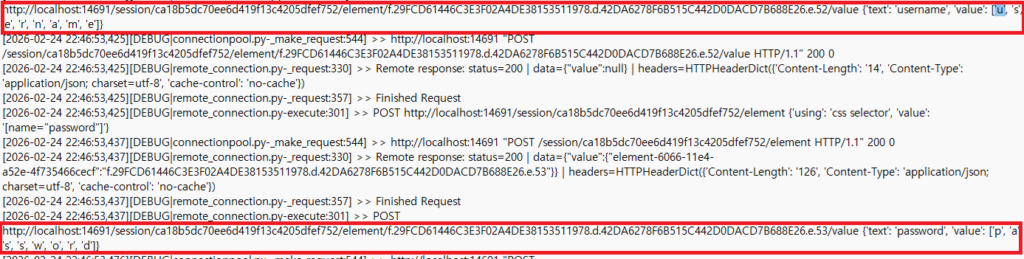
디버그 로그의 경우 로그인과정에서 입력할 문자열, 즉 아이디와 비밀번호도 평문으로 나오기 때문에, 공유 전 이 부분을 확인해 지워주셔야 합니다.
도커 사용설명서
설치 및 설정
이 프로그램은 원래 저 혼자 리눅스에서 도커화 하여 사용하던 프로그램이었습니다. docker compose로 간단하게 설치할 수 있으며, 리눅스 CLI환경을 염두에 두고 있기 때문에 Selenium Hub를 이용하도록 설계되어 있습니다.
services:
mysafetyreport:
container_name: safetyreport
image: fentanest/safetyreport:latest
env_file:
- .env
volumes:
- ./data:/app/data
restart: always환경 설정값은 .env파일을 사용합니다.
[SELENIUM]
remotepath = http://localhost:4444
[LOGIN]
username = your_username
password = your_password
[TELEGRAM]
telegram_token = your_token
chat_id = your_chat_id
[SETTINGS]
interval = 60
max_retry = 10
max_empty_pages = 3
log_level = INFO
TZ = Asia/Seoul
[GOOGLESHEET]
sheet_key = your_sheet_key- remotepath : Selenium Hub 주소
- username : 안전신문고 ID
- password : 안전신문고 PW
- telegram_token : 텔레그램 봇 토큰
- chat_id : 텔레그램 봇 사용할 계정 chat_id
- interval : 장애 시 다시 시도할 간격(초)
- max_retry : 장애 시 최대 시도할 횟수
- max_empty_pages : 윈도우 앱의 ‘조건부 탐색’ 기능. 신고내역에서 ‘진행’상태의 신고건이 한개도 없는 페이지를 설정한 숫자만큼 만날 경우 신고건 탐색 종료.
- log_level = DEBUG 설정 시 상세한 로그 기록
- TZ = Asia/Seoul (다른 시간대 사용할 이유가 없잖아요)
- sheet_key = 구글 스프레드 시트 연동 시 연동할 스프레드 시트의 주소
구글 스프레드 시트 사용에 필요한 JSON키파일은 ./data/auth/gspread.json 경로 생성 후 직접 넣어주시면 됩니다.
실행 옵션 (start.py)
start.py 스크립트 실행 시 다음과 같은 인자를 사용하여 동작을 제어할 수 있습니다. Docker 환경에서는 docker exec -it <컨테이너_이름> python start.py [옵션] 형태로 사용할 수 있습니다.
--force: 이미 처리된 신고 건을 포함하여 모든 상세 내역을 다시 크롤링합니다.--reset: 기존 데이터베이스 파일을 모두 삭제하고 처음부터 다시 시작합니다. (주의: 모든 데이터가 사라집니다.)--min: ‘진행’ 상태의 신고가max_empty_pages설정값에 지정된 페이지 수만큼 연속으로 나오지 않으면 크롤링을 조기 종료합니다.--p <페이지>: 지정된 페이지만 크롤링합니다.- 예시:
python start.py --p 5(5페이지 한 페이지만 크롤링)
- 예시:
--p <시작페이지>-<끝페이지>: 지정된 페이지 범위만 크롤링합니다.- 예시:
python start.py --p 5-10(5페이지부터 10페이지까지 크롤링)
- 예시:
--p <페이지1>,<페이지2>,...: 쉼표로 구분된 특정 페이지만 크롤링합니다.- 예시:
python start.py --p 5,7,9(5, 7, 9 페이지를 크롤링)
- 예시:
- 모든 페이지는
30개씩 보기상태에서 계산됩니다.
Crontab 사용
crontab에 /usr/bin/docker exec safetyreport python /app/start.py를 입력하여 주기적으로 실행할 수 있습니다.
텔레그램 봇과 연동 시, 주기적으로 신고내역을 긁어와 신규답변내용을 알람받을 수 있습니다.
0 9,12,18 * * * /usr/bin/docker exec safetyreport python /app/start.py텔레그램 봇
.env값에 텔레그램 봇 토큰과 ID 를 제대로 넣었다면 윗 단락의 윈도우 설명과 동일한 기능의 봇이 작동합니다.
crontab을 활용하여 주기적으로 자동 크롤링을 지시하면 거의 최신화되어있는 DB에서 편하게 검색 등을 수행하고 야외환경에서도 상습위반차를 식별해낼 수 있습니다.
변경 이력
2024/05 ~ 2025/09 – v1.0.x
- Github Repository 생성 및 습작 업로드
- 로깅 모듈 추가
- 텔레그램 봇 기능 추가
2025/09/10 – 윈도우용으로 레포 추가
2025/11/11 – v1.1
- import 구문 오류 수정
2026/01/02 – v1.2
- 텔레그램 봇 정보 미입력(비활성화) 시에도 봇을 실행해서 app.py 오류 메세지 띄우던 현상 수정
- 불법주정차 시 ‘수용’여부 판단 기준 추가, 버스전용차로 메뉴 추출 로직 수정
2026/01/30 – v1.2.1
- 구글 시트 업로드 시 3회까지 재시도하도록 수정, 500행 단위로 chunk 업로드 기능 추가
2026/02/25 – v1.2.2
- 안전신문고 신고내역 첨부파일 이미지 추출로직 수정